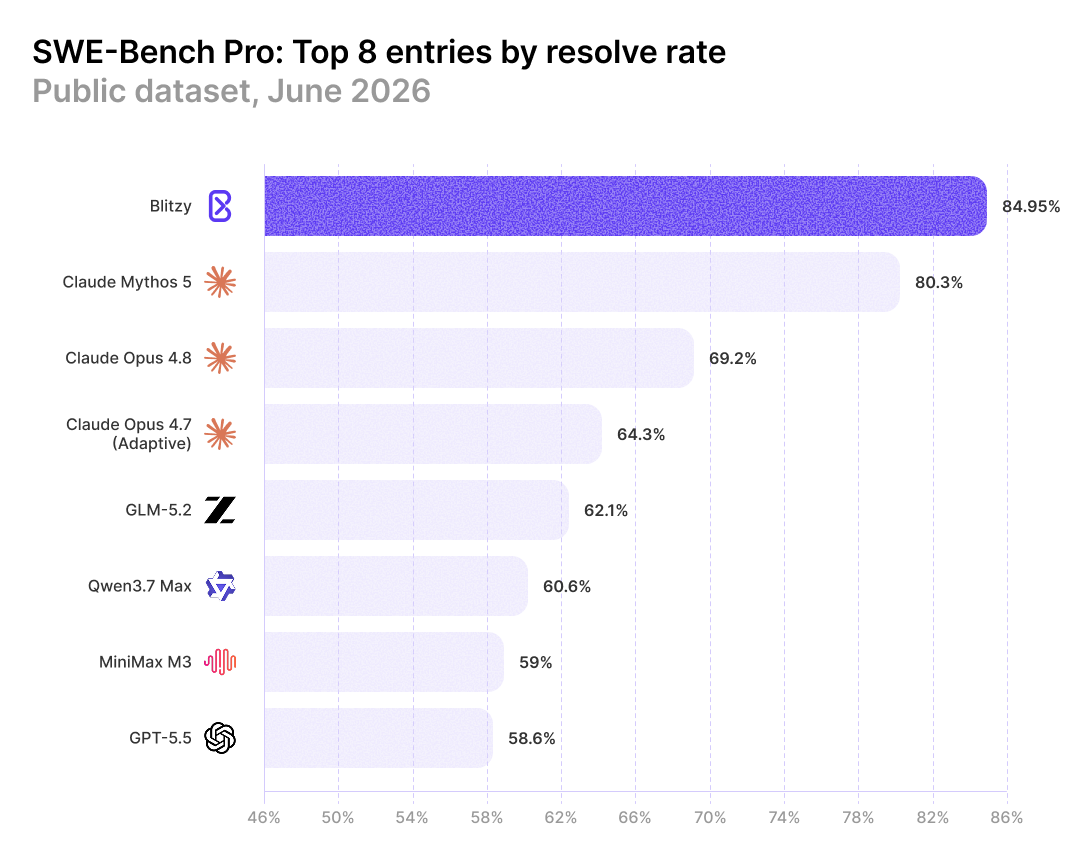
Blitzy Scores a Record 84.95% on SWE-Bench Pro
Jun 26, 2026 • Dr. Neeraj Deshmukh • 4 min read

Blitzy set a new best-in-class score on SWE-Bench Pro Public, outperforming Mythos with older generation models intelligently orchestrated together.
While the AI landscape has changed considerably in three months, one fact has not.
Blitzy still holds the record on SWE-Bench Pro Public, but now with a score of 84.95%.
The closest result behind us belongs to Anthropic's latest model Mythos at 80.3%.
What makes the result more noteworthy is how we did not use Mythos to achieve this record. Blitzy fused a set of models a generation behind the current frontier: Opus 4.8, GPT 5.5, Sonnet 4.6, and GPT 5.4 Mini. On its own, Opus 4.8 scores 69.2% on this benchmark. The difference in performance comes from the system surrounding the models, not the models themselves.
The Record & Validation
Blitzy's record is approximately an 18-point gain on the 66.5% score we posted in March.
For validation, we brought in Quesma again, who audited the 66.5% run and already knew our setup. We provided our trajectories, methodology, and research team. They analyzed the hardest tasks and checked for anomalous behaviors and internet leakage.
Quesma has independently verified that the results are clean.
Why This Is Important
SWE-Bench Pro remains the gold standard for measuring AI software engineering capability. The benchmark measures a system's precision and power with real problems enterprise developers solve regularly.
In our last published SWE-Bench Pro audit, we argued that the system around the model matters more than the model itself. The 84.95% score further strengthens that position.
Blitzy is the system that understands your codebase and orchestrates the work.
This is the value of an abstraction layer. An enterprise should not have to track which model leads this quarter or hand-craft a harness to extract performance out of it. That work pulls engineers off their core product, and it resets every time a new model ships. Blitzy is the abstraction layer that removes this problem. Steered by an enterprise's unique context and organizational intent, we deliver production-grade results at enterprise speed, scale, and quality, while the models underneath change as often as they need to.
Why Multi-Model Systems Outperform Single Frontier Models
Our guiding principle since day one in 2023 is that taking advantage of all the frontier models beats any single model in isolation. For the enterprise, leveraging all frontier models removes dependencies. Build on one model and you inherit its price and its availability. If that price climbs or a model like Fable is taken offline, you are left exposed. A system that draws on every major model spreads risk, so no provider, price change, or deprecation can impact the work.
Our March audit showed how we achieved our original record of 66.5%. Quesma ran the state-of-the-art base model on the same tasks at maximum reasoning effort, expecting spectacular failures. What they found was more subtle. Almost every wrong answer was close. For instance, the system found the right part of a codebase and wrote a reasonable patch but failed on edge and corner cases.
A single model works from one pass through the code with a limited context window. Blitzy leverages an enterprise's entire codebase as context to build a unique, dynamic knowledge graph. Every task our platform performs draws on this knowledge graph, so when an agent hits a boundary condition that trips a single model, Blitzy has the context to solve problems effectively. Fusing frontier models together takes that further: several models in one build, each covering the others' blind spots, grounded in a shared understanding of the system. That institutional context and fusion is how a stack of older models outperformed a model so powerful that it cannot be released to the public for fear of widespread panic.
What Is Blitzy?
Blitzy is an autonomous enterprise software development platform built for large, legacy codebases. Before writing code, Blitzy spends days of uninterrupted compute reverse-engineering your global estate into a dynamic knowledge graph: every dependency, pattern, and architectural decision across codebases upwards of 100 million lines, mapped and queryable.
Grounded in that understanding, the orchestration engine decomposes a project from your team's spec and recruits thousands of specialized agents in parallel, often executing more than 100,000 agent-to-agent calls on a single job. Those agents fuse the strengths of models from OpenAI, Anthropic, and Google, pulling just-in-time context from the knowledge graph as they build.
Autonomy at scale only matters if the output is correct, so Blitzy spends more compute power verifying its work rather than just writing it. Execution pauses at hard checkpoints where review agents inspect the work, classify risk, and fix problems before a build continues. The result is project-level, production-grade code that merges cleanly, up to five times faster.
Every Blitzy run strengthens this knowledge graph, so the enterprise keeps institutional memory that no engineer can carry out the door, and each project is less expensive than the last.
Quarters of work ship in days.
Intelligent Model Fusion From Inception, Not Bolted On
Multi-model fusion has been part of Blitzy since day one. We built the platform to combine models and ground them in a dynamic knowledge graph. It was the founding design decision, not something we bolted on later.
Many of the strongest agent products started as single-model harnesses. Factory and Devin are the closest examples, and both are now adding the ability to route between models. Routing is useful, but it is not fusion. It picks one model for a task.
Blitzy uses one model family to check the work of another and anchors them to a shared model of the codebase. Bolting model selection onto a single-model harness is not the same as designing for intelligent fusion from inception.
The Blitzy platform's SWE-Bench Pro benchmark results verify that gap.
Conclusion
Foundation models are getting better quickly, and Blitzy is best positioned to reap the benefits.
Our SWE-Bench Pro score is another strong data point.
What it confirms is the thesis we have held since day one: serious software engineering requires a deep understanding of the codebase and a dynamic, multi-model architecture to match.
Blitzy is changing the unit of work and delivering the true promise of AI in software development.

